

Three-dimensional object detection_Tengun-label
- Tengun-label
- Sep 6, 2022
- 4 min read
Updated: Aug 30, 2023
◉Background
Thanks to advances in sensing technology, it has become easier to obtain 3D data. Among them, Lidar is especially active in various situations.
Compared to 2D data, 3D data provides another dimension of "distance" information. This makes it possible to understand the real world more deeply.
3D data + deep learning solved various real problems.
◉Applications of 3D point clouds
You can get 3D point cloud from lidar.
3D point cloud + deep learning is important for autonomous driving (cars, robots).
Deep learning enables automatic processing of 3D point cloud data. It can be applied in the following tasks:
3D Point Cloud Segmentation
3D Object Detection
3D Object Classification
3D Object Tracking
【Autonomous Driving Case: Object Detection with Lidar Data】

【Augmented Reality case study】

【Example of Quality Analysis: Comparing Design with Reality】

【3D Environment Reconstruction Case Study: Reconstructing an Environment】
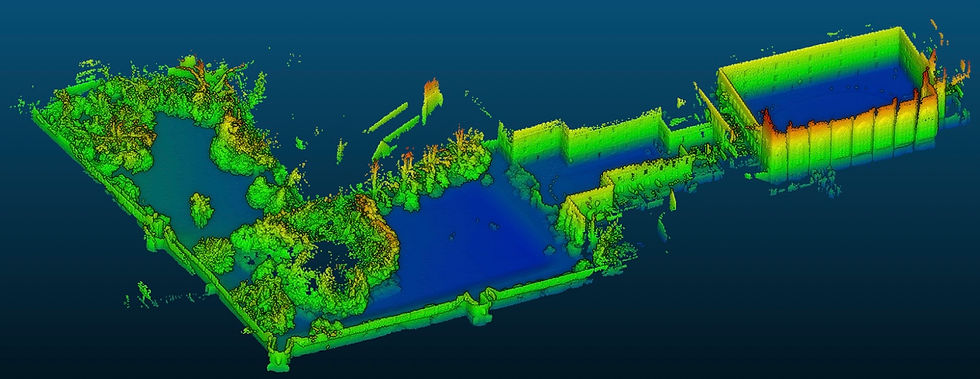
【SLAM Case Study: Calculating Your Location in Real Time】

【Distance measurement example: Measure distance remotely】

◉Application of 3D point cloud: 3D object detection
When driving automatically, it is necessary to detect surrounding objects (such as cars). This allows the car to “understand” its surroundings.
:Technique
Performs 3D object detection based on data obtained from sensors mounted on the vehicle
3D object detection can detect object type, size and distance
3D object detection allows the car to “understand” its environment and act accordingly
【Object detection: detect the bounding box of a 3D object】

※A three-dimensional bounding box consists of eight points surrounding an object.
■Sensor in car
CAMERA: Camera for acquiring RGB data
LIDAR: Sensor for acquiring 3D point cloud using Laser
RADAR: A sensor for judging distance using voice
LIDAR directly provides three-dimensional information, which is useful for 3D object detection. CAMERA provides 2D data, but for 3D object detection it's not as straightforward as a point cloud.
■Sensors for acquiring data

【3D object detection: Model】
After the point cloud is acquired, 3D object detection is performed by deep learning. Here are some 3D object detection deep learning models.
PointNet
VoxelNet
PointPillars
IA-SSD
BEVFusion
【3D object detection: PointNet】
◉PointNet handles point cloud data directly

■PointNet model processing process
Point cloud as input
Transform the input with the Transform Module for easier processing
Multilayer perceptron (mlp) layers to expand feature dimensionality
Transform again with Transform Module
Combining mlp and max pooling layers to squeeze results
◉Transform Module

PointNet is the first milestone to process 3D data with deep learning
PointNet uses the Transform module to appropriately transform and process the point cloud (similar to when humans change their viewpoint and observe an object)
PointNet uses point cloud data directly, so accuracy and efficiency are low
Expressive power is weak as it is as a point cloud
There is a lot of wasteful processing due to the large number of points
【3D object detection: VoxelNet】
■Processing point clouds with voxels in basic units
Use voxels to delimit space
Voxel generates Voxel features by interior points
3D Convolution Neural Network (CNN) to process features
Squeeze out the bounding box of the target
End-to-End Learning for Point Cloud Based 3D Object Detection (CVPR 2018)

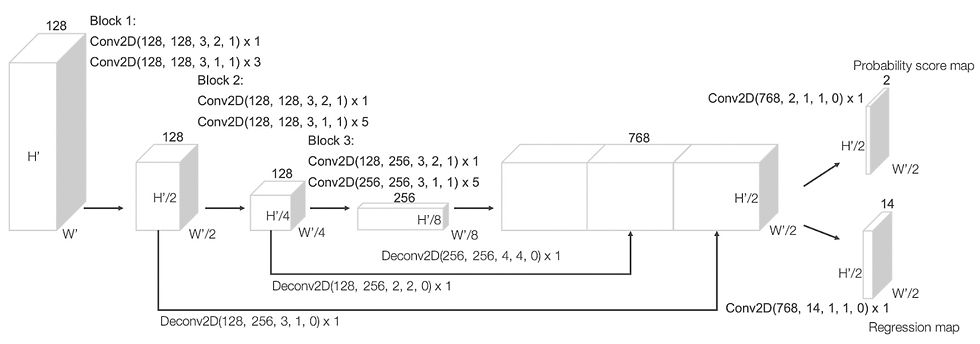
Efficiency is higher than PointNet because it processes in voxel units
Carefully designed the feature extraction part of Voxel
Transform module is no longer available compared to PointNet
The voxel size is fixed, so large variations in point cloud density (e.g. lidar data) reduce the accuracy of the VoxelNet.
3D CNN is used, so the processing speed is not high
【3D object detection: PointPillars】
◉The shape of lidar data is similar to cate

◉PointPillars: Use pillars (long and thin voxels) as basic units

■Processing point clouds with Pillars in base units
Use Pillars to divide space
Pillars generate Pillars features by interior points
2D Convolution Neural Network (CNN) to process features
High processing speed (40 FPS or more) because it uses 2D CNN that squeezes out the target bounding box
◉Processing using a Neural Network with a 2D Pyramid structure

PointPillars is a model designed for Lidar
2D CNN is used, so the processing speed is high (40 FPS or more)
High accuracy of object detection on lidar data
【3D object detection: IA-SSD】
■Not all points in the lidar point cloud are equally important
The goal object is of high importance
Background is less important
■Sampling according to importance
Critical points should be sampled frequently
Insignificant points should be sampled infrequently
■Proposed sampling method
Train the sampling module to perform the best sampling

■Proposed sampling method
Sampling frequently for the target class in the MLP layer
The closer to the object center, the higher the sampling frequency
■Advantages of this method
You can oversample the points you want and undersample the points you don't.
Result: High-speed and high-precision object detection (80 FPS or more)
【3D object detection: BEVFusion】
BEVFusion: Object detection by fusing camera data and lidar data
The previous method used only Lidar, but in the case of autonomous driving, camera data can be used
Advantages: As the amount of information increases, improvement in accuracy can be expected.
Difficult point: The characteristics of the RGB data of the camera and the point cloud data of Lidar are different, so it is difficult to fuse them
◉BEVFusion: Fusion of camera and lidar data in BEV space

◉BEVFusion model structure

◉Project camera data into BEV space
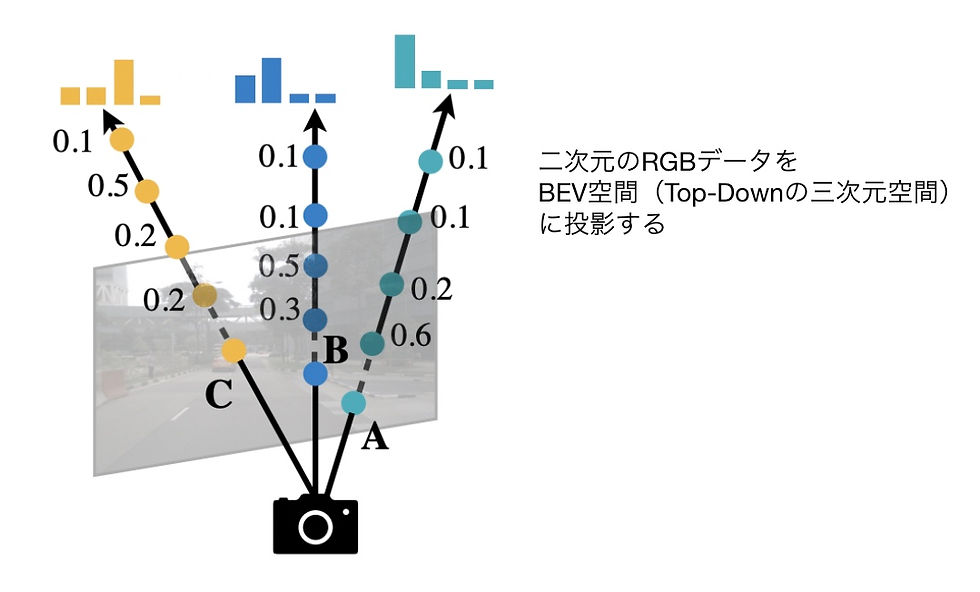
※Project 2D RGB data into BEV space (Top-Down 3D space)

※Perform object detection with all cameras and point clouds simultaneously
RGB image and point cloud have different properties, difficult to fuse
BEVFusion proposed a fusion method
BEVFusion is more accurate than lidar-only methods
【Inquiry】
Please contact Tengun-label for consultation on various sensing and data analysis, including AI and 3D image processing.
Tengun-label Co., Ltd.
Headquarters: Room 1014, Nagatani Revure Shinjuku, 4-31-3 Nishi-Shinjuku, Shinjuku-ku, Tokyo
Branch office: 6-6-2 Nishi-Shinjuku, Shinjuku-ku, Tokyo Shinjuku Kokusai Building 4F Computer Mind
E-mail:info@tengun-label.com
TEL:080-5179-4874

Comments